
常见面试问题总结
1、如何解决样本不均衡的问题:
样本的过采样和欠采样。
过采样:将稀有类别的样本进行复制,通过增加此稀有类样本的数量来平衡数据集。该方法适用于数据量较小的情况。
存在问题:过拟合欠采样:从丰富类别的样本中随机选取和稀有类别相同数目的样本,通过减少丰富类的样本量啦平衡数据集。该方法适用于数据量较大的情况。
存在问题:可能会存在信息减少的问题。因为只是利用了一部分数据,所以模型只是学习到了一部分模型。SMOTE算法:对少数类别样本进行分析和模拟,并将人工模拟的新样本添加到数据集中,进而使原始数据中的类别不再严重失衡。该算法的模拟过程采用了KNN技术,模拟生成新样本的步骤如下:
1) 采样最邻近算法,计算出每个少数类样本的K个近邻;
2) 从K个近邻中随机挑选N个样本进行随机线性插值;
3) 构造新的少数类样本;
4) 将新样本与原数据合成,产生新的训练集;
使用多个分类器进行分类。
集成学习:Boosting和Bagging思想
将二分类问题转换成其他问题。
可以将不平衡的二分类问题转换成异常点检测,或者一分类问题(可使用one-class svm建模)
改变正负类别样本在模型中的权重
使用代价函数学习得到每个类的权值,大类的权值小,小类的权值大。刚开始,可以设置每个类别的权值与样本个数比例的倒数,然后可以使用过采样进行调优。
2、对数据进行归一化的好处
- 归一化后加快了梯度下降求最优解的速度,数据归一化后,最优解的寻优过程明显变得平缓,更容易正确的收敛到最优解。
- 归一化有可能提高精度
3、机器学习算法常用的指标
错误率与精度评估方法
错误率与精度常用于分类任务,错误率是测试样本中分类错误的样本数占总样本数的比例,精度是测试样本中分类正确的样本数占总样本数的比例。用测试数据集的精度来表示模型的泛化能力在正负样本比例相差较大的时候就不适用
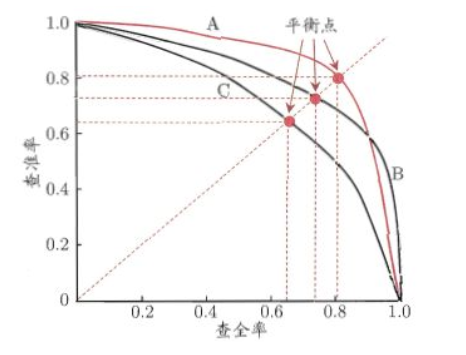
了。P-R曲线
混淆矩阵:
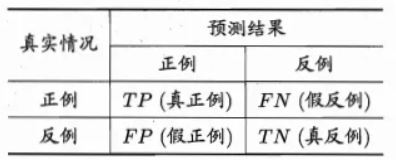
TP:真正例,正确肯定的数目;
FN:假正例,漏报,没有正确找到的匹配的数目;
FP:真反例,误报,给出的匹配是不正确的;
TN:假反例,正确拒绝的非匹配对数;
精确率P:是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;(挑出的西瓜有多少比例是好瓜)
召回率R:是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。(所有好瓜中有多少比例被挑选了出来)

P_R曲线以精确率为纵坐标,以召回率为横坐标。

ROC曲线
1) 为什么要用ROC曲线?- 在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大
于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正
类,也就是提高了识别出的正例占所有正例的比类,即TPR,但同时也将更多的负实例当作了正实例,即提
高了FPR。为了形象化这一变化,引入ROC,ROC曲线可以用于评价一个分类器。 - 在类不平衡的情况下,如正样本90个,负样本10个,直接把所有样本分类为正样本,得到识
别率为90%。但这显然是没有意义的。单纯根据Precision和Recall来衡量算法的优劣已经不能表征这种病
态问题。
2) ROC曲线
绘制ROC曲线的思想与P-R曲线一致,对学习模型估计测试样本为正样本的概率从大
到小排序,然后根据概率大小依次设置阈值,认为大于阈值的测试样本为正样本,小于阈
值的测试样本为负样本,每一次阈值设置都计算“真正例率”(True Positive Rate,简称
TPR)和“假正例率”(False Postive Rate,简称FPR)。ROC曲线横坐标为假正例率,纵坐标为真正例率。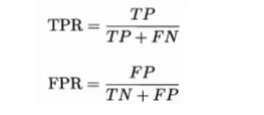
3)什么是AUC?
AUC值为ROC曲线所覆盖的区域面积,面积可以通过梯度面积法求解。显然,AUC越大,分类器分类效果越好。假正例率对应的是真实负样本中分类结果为正样本的比例,真正例率对应的是真实正样本中分类为正样本的比例。
假正例率和真正例率的增长性具有互斥性,每次都只能增加一个,且每次增加的梯度为1/m,横坐标和纵坐标共增加了m次。- 在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大
4、常见损失函数的总结*
0-1损失函数(感知机算法)
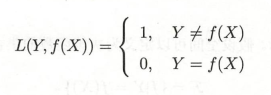
0-1损失函数可以直观的刻画分类的错误率,但是因为其非凸,非光滑的特点,使得算法很难对其进行直接优化。
Hinge损失函数(SVM)
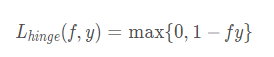
Hinge损失函数是0-1损失函数的一个代理损失函数,也是其紧上界,当 fy ≥ 0 时,不对模型做惩罚。可以看到,hinge损失函数在fy=1 处不可导,因此不能用梯度下降法对其优化,只能用次梯度下降法。
Logistic损失函数
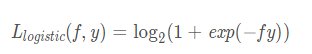
Logistic损失函数是0-1损失函数的另一个代理损失函数,它也是0-1损失函数的凸上界,且该函数处处光滑。但是该损失函数对所有样本点都惩罚,因此对异常值更加敏感。
交叉熵损失函数
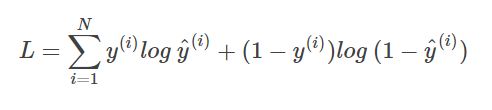
交叉熵损失函数也是0-1损失函数的光滑凸上界。
指数损失函数(AdaBoost)

指数损失函数是AdaBoost里使用的损失函数,同样地,它对异常点较为敏感,鲁棒性不够
平方损失函数(最小二乘法)
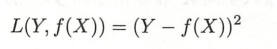
平方损失函数是光滑的,可以用梯度下降法求解,但是,当预测值和真实值差异较大时,它的惩罚力度较大,因此对异常点较为敏感。
绝对损失函数
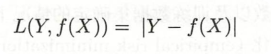
绝对损失函数对异常点不那么敏感,其鲁棒性比平方损失更强一些,但是它在 f = y 处不可导.
Huber损失函数
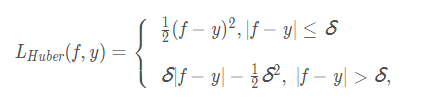
Huber损失函数在 ∣f−y∣ 较小时为平方损失,在 ∣f−y∣ 较大时为线性损失,且处处可导,对异常点鲁棒性较好。
5、 为什么梯度是函数变化最快的方向?*
曲面中点的方向导数有无数个,当方向导数与梯度方向一致时,该导数值取得最大,等价于该
点在梯度方向具有最快的变化值。梯度方向是函数值增加最快的方向,梯度的反方向是函数值减小最
快的方向。
6、 KNN伪代码

7、K-means伪代码

