
随机森林(RF)
随机森林是Bagging的一个扩展变体,盯在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
偏差与方差
1、偏差:度量模型的期望预测与真实结果的偏离程度,刻画了模型本身的拟合能力。
2、方差:度量了同样大小的训练集的变动导致学习能力的下降,刻画了数据扰动所造成的影响。
3、噪声:表达了当前任务上任何模型所能达到的期望泛化误差的下界,刻画了学习问题本身的难度。
欠拟合:偏差主导泛化误差
过拟合:方差主导泛化误差
Boosting侧重降低偏差,Bagging侧重降低方差。随机森林的主要作用是降低方差,降低模型的复杂度。
随机森林模型建立步骤
(1)对原始数据集进行可放回随机抽样成K组子数据集;
(2)从样本的N个特征随机抽样m个特征;
(3)对每个子数据集构建最优学习模型
(4)对于新的输入数据,根据K个最优学习模型,得到最终结果,对于分类任务,随机森林是多数表决。对于回归任务,随机森林是简单平均。
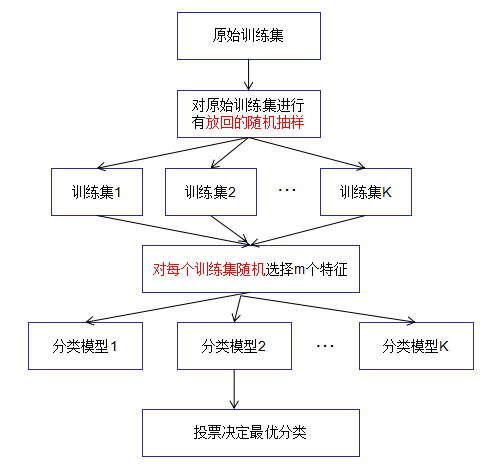
1、对训练集进行有放回地随机抽样。(求同存异)
1) 如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的,这样的话完全没有bagging的必要。(每颗决策树只有同,没有异)
2) 如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,(随机森林中的每颗决策树只有异,没有同)
这样每棵树都是”有偏的”,都是绝对”片面的”,也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是”求同”,因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是”盲人摸象”。
2、每次构建决策树时,对特征进行随机抽取。推荐值k=log2d
使子数据集间有不同的子特征,我们把不同的特征代表不同的领域,从而在不同领域构建不同模型,得到比较全面的结果。
相关性
随机森林的相关性包括子数据集间的相关性和子数据集间特征的相关性。相关性在这里可以理解成相似度,若子数据集间重复的样本或子数据集间重复的特征越多,则相关性越大。
随机森林分类效果(错误率)与两个因素有关:
1、森林中任意两棵树的相关性:相关性越大,错误率越大;
2、森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
模型评估方法
随机森林的论文中证明了袋外数据(OOB)误差估计是一种可以取代测试集的误差估计方法,即袋外数据误差是测试数据集误差的无偏估计,因此可以用OOB数据用来检测模型的泛化能力。
1、袋外数据误差估计模型
2、交叉验证率估计模型
优缺点
RF的主要优点有:
1) 训练可以高度并行化,对于大数据时代的大样本训练速度有优势。个人觉得这是的最主要的优点。
2) 由于可以随机选择决策树节点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型。
3) 在训练后,可以给出各个特征对于输出的重要性
4) 由于采用了随机采样,训练出的模型的方差小,泛化能力强。
5) 相对于Boosting系列的Adaboost和GBDT, RF实现比较简单。
6) 对部分特征缺失不敏感。
RF的主要缺点有:
1)在某些噪音比较大的样本集上,RF模型容易陷入过拟合。
- 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果。
参考链接:
https://blog.csdn.net/yangyin007/article/details/82385967
https://www.sohu.com/a/279136744_163476
